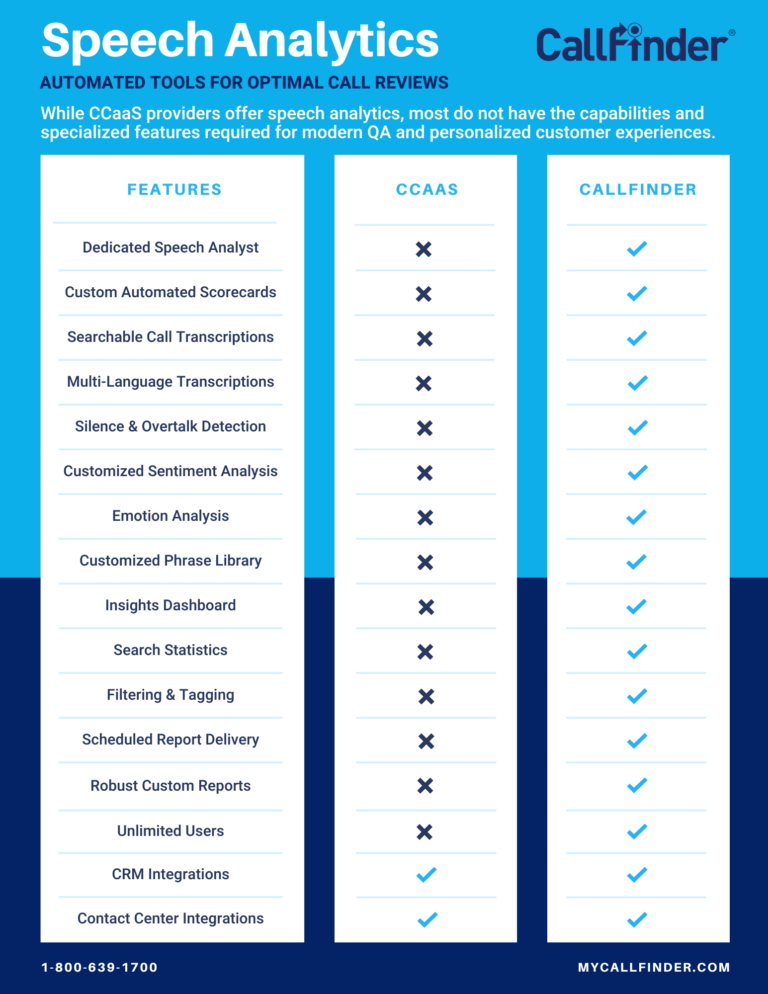
In the realm of artificial intelligence, few innovations have captured the imagination and fascination of researchers and enthusiasts as much as large language models (LLMs). These models possess an uncanny ability to decipher, generate, and manipulate human language with an adeptness that blurs the line between artificial and human intelligence. But what exactly constitutes a large language model, and how does it wield its linguistic prowess?
Unveiling the Foundations
At its essence, a large language model is a sophisticated AI system designed to understand, process, and generate text just like humans. These models are constructed upon intricate network architectures, with deep learning algorithms forming the foundation of their functionality. What distinguishes large language models from other models is their sheer scale and complexity.
By training on vast datasets comprising of billions of words, these models can encapsulate the intricate nuances and subtleties of language usage. But how close is it to human language? That all depends on the data.
The Anatomy of Training & Data
The journey of a large language model begins with data – large amounts of it. These models ingest immense amounts of text from a plethora of sources, including books, articles, websites, and social media posts. Through a process known as pre-training, the model learns to predict the next word in a sequence based on the context provided by the preceding words. This foundational task, often referred to as language modeling, serves as the first layer upon which the model’s understanding of language is built.
As the model undergoes training, it fine-tunes the weights and parameters of its neural network, continually refining its ability to generate coherent and contextually relevant text. The training process is intensive, demanding formidable computational resources and substantial time investments.
Unleashing Generative Power
Once trained, a large language model unleashes its generative prowess across a myriad of natural language processing (NLP) tasks. One of its most notable capabilities is text generation. By providing a prompt or an initial phrase, users can stimulate the model to produce text that adheres to the given context or theme.
Whether it’s completing sentences, crafting story plots, composing poetry, or even generating code snippets, large language models are astonishingly proficient in mimicking human language patterns. This generative prowess has found applications in diverse domains, including content creation, virtual assistants, chatbots, and creative writing assistance.
Navigating Ethical Terrain
While the capabilities of large language models are undeniably impressive, they also pose ethical considerations and technical challenges. One primary concern centers on the potential for bias, which may perpetuate societal prejudices ingrained in the training data. Mitigating these biases requires careful curation of training datasets and the implementation of fairness-aware algorithms.
Moreover, large language models can be susceptible to exploitation for negative purposes. This includes generating misinformation, impersonating individuals, or manipulating public opinion. Safeguarding against such misuse requires robust measures for authentication, verification, and content moderation.
Looking Toward the Future
Despite the complexities and challenges associated with large language models, their potential for positive societal impact is profound. From enhancing accessibility to revolutionizing healthcare, these AI-powered systems hold the promise of reshaping various facets of human existence.
As research and development in natural language processing continue, even more sophisticated language models are sure to come. However, it is imperative to approach their development and deployment with care. This ensures that humans utlize LLMs responsibly and ethically to serve the collective betterment of humanity.
In conclusion, large language models stand as testament to the remarkable strides made in the field of artificial intelligence. LLMs offer a glimpse into a future where the boundaries between human and machine intelligence blur ever further. As we gain a deeper understanding into these transformative technologies, we must learn to leverage their potential responsibly. This means we must use AI to foster progress and innovation while safeguarding against potential pitfalls.
To learn more about the technology CallFinder uses in our solution, book a short demo of our speech analytics software.